
This tutorial will guide you through the process of creating a fault-tolerant, scalable, and highly available PostgreSQL cluster from scratch using Ansible automation on Rocky Linux release 9. This guide is applicable if you are running a CentOS, RHEL or Oracle Linux 9 in your environment.
By the end of this guide, you'll have a robust PostgreSQL HA cluster ready for your production use.
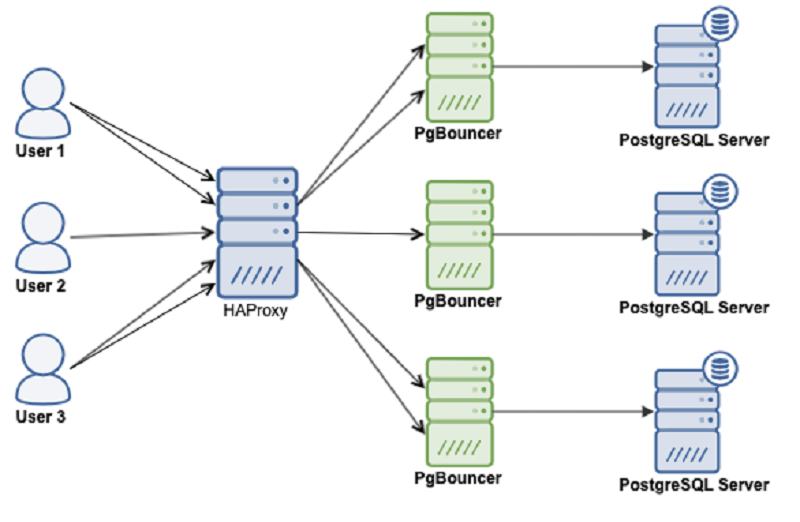
PostgreSQL HA cluster is comprised of the following components:
- Patroni is a cluster manager used to customize and automate deployment and maintenance of PostgreSQL HA (High Availability) clusters.
- etcd is a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines. We will use etcd to store the state of the PostgreSQL cluster.
- PgBouncer is an open-source, lightweight, single-binary
connection pooler for PostgreSQL. PgBouncer maintains a pool of
connections for each unique user, database pair. It’s typically
configured to hand out one of these connections to a new incoming client
connection, and return it back in to the pool when the client
disconnects.
- HAProxy is a free and open source software that provides a high availability load balancer and reverse proxy for TCP and HTTP-based applications that spreads requests across multiple servers.
- Keepalived implements a set of health checkers to dynamically and adaptively maintain and manage load balanced server pools according to their health. When designing load balanced topologies, it is important to account for the availability of the load balancer itself as well as the real servers behind it.
The sole purpose of this guide is to automate the entire setup process with Ansible, and to make PostgreSQL database highly available in order to avoid any single point of failure.
PostgreSQL Cluster Hardware Requirements
Patroni/Postgres system requirements:
2 Core CPU
4 GB RAM
80 GB HDD
ETCD system requirements:
2 Core CPU
4 GB RAM
80 GB SSD
PgBouncer system requirements:
2 Core CPU
4 GB RAM
20 GB HDD
PgBouncer is just a connection pooler for postgres database, and it doesn't require much disk space.
HAProxy system requirements:2 Core CPU
4 GB RAM
80 GB HDD
The above HAProxy system requirements is given based on an average of 1000 connections per second. For a larger number of connections, the memory and CPU have to be increased in the ratio of 1:2 (memory in GB = 2 x number of CPU cores). The CPU cores have to be as fast as possible for better HAProxy performance.
Number of nodes requirements
It is recommended to have an odd number of nodes in a patroni cluster. An odd-size cluster tolerates the same number of failures as an even-size cluster but with fewer nodes. The difference can be seen by comparing even and odd sized clusters:
The same odd number of nodes recommendation goes for etcd cluster as
well. Safely, you can say 3-nodes cluster is better, but 5-nodes cluster
is good to go.
Production environment
You can take an example of the following recommended set up to build a highly available patroni cluster for your production use.
Solution 1:
- Take 3-nodes for patroni cluster - install (postgres, patroni, pgbouncer, haproxy, keepalived) on these three machines.
- Take 3-nodes for etcd cluster - install etcd on these three machines.
This will become a 6-nodes patroni cluster, which you can scale up in future by adding more nodes into your patroni and etcd cluster to meet your production needs.
Solution 2:
- Take 3-nodes for patroni cluster - install (patroni+postgres) on these three machines.
- Take 3-nodes for etcd cluster - install only (etcd) on these three machines.
- Take 2-nodes for HAProxy - install (haproxy+keepalived+pgbouncer)on these two machines.
This will become a 8-nodes patroni cluster which you can scale up in future by adding more nodes into your patroni and etcd cluster to meet your production needs.
Basic environment for PostgreSQL HA cluster with Patroni
For the sake of this guide, we will go with the minimum requirement to set up a 3-node patroni cluster on three separate virtual machines:
We will install (PostgreSQL, Patroni, etcd, pgbouncer, haproxy, and keepalived) on each of these three nodes.
Prepare Your Ansible Control Node
sudo nano /etc/hosts
Make sure you replace highlighted text with yours. Save and close the editor when you are finished.127.0.0.1 localhost192.168.0.10 pg_node1 pgnode1
192.168.0.11 pg_node2 pgnode2
192.168.0.12 pg_node3 pgnode3
192.168.0.200 shared_ip haproxy
Install Ansible
sudo apt update
sudo apt install -y ansible jq
sudo dnf update
sudo dnf install -y ansible jqSet Up SSH Keys
ssh-keygenssh-copy-idsshuser@pg_node1
ssh-copy-idsshuser@pg_node2
ssh-copy-idsshuser@pg_node3
ssh192.168.0.10
ssh192.168.0.11
ssh192.168.0.12
sshpg_node1
sshpg_node2
sshpg_node3
Create Ansible Directory Structure
mkdir postgres_ansible
cd postgres_ansible
mkdir -p roles/{common,postgres,etcd,patroni,haproxy,pgbouncer,keepalived}
mkdir -p roles/common/tasks
mkdir -p roles/postgres/tasks
mkdir -p roles/etcd/tasks
mkdir -p roles/patroni/tasksmkdir -p roles/haproxy/tasksmkdir -p roles/pgbouncer/tasksmkdir -p roles/pgbouncer/filesmkdir -p roles/keepalived/tasks
Add following content into ansible.cfg file:nano ansible.cfg
[defaults]Save and close the editor when you are finished.
inventory = hosts
Populate hosts file with the required variables like below:nano hosts
[dbservers]Make sure you replace highlighted text with yours. Save and close the editor when you are finished.
pg_node1 ansible_host=192.168.0.10
pg_node2 ansible_host=192.168.0.11
pg_node3 ansible_host=192.168.0.12
[dbservers:vars]
ansible_user=administrator
Create Ansible Common task
nano roles/common/tasks/main.yml
- name: Enable NOPASSWD for sudo group
lineinfile:
path: /etc/sudoers
regexp: '^%wheel\s+ALL=\(ALL:ALL\) ALL$'
line: '%wheel ALL=(ALL) NOPASSWD: ALL'
- name: Set SELinux to permissive mode
ansible.posix.selinux:
state: permissive
- name: Add firewall rules
firewalld:
port: "{{ item.port }}"
zone: public
permanent: yes
state: enabled
loop:
- { port: '5432/tcp' }
- { port: '6432/tcp' }
- { port: '8008/tcp' }
- { port: '2379/tcp' }
- { port: '2380/tcp' }
- { port: '5000/tcp' }
- { port: '5001/tcp' }
- { port: '7000/tcp' }
- name: Allow http
firewalld:
service: http
permanent: yes
state: enabled
- name: Allow keepalived
firewalld:
rich_rule: 'rule protocol value="vrrp" accept'
permanent: yes
state: enabled
- name: Reload firewall
command: firewall-cmd --reload
- name: Set timezone
community.general.timezone:
name: Asia/Karachi
- name: Copy /etc/hosts file
ansible.builtin.copy:
src: /etc/hosts
dest: /etc/hosts
owner: root
group: root
Create Ansible PostgreSQL task
nano roles/postgres/tasks/main.yml
- name: Install epel repo
ansible.builtin.dnf:
name:
- epel-release
- dnf-plugins-core
- yum-utils
- name: Enable powertools
ansible.builtin.command:
cmd: dnf config-manager --set-enabled crb
- name: Install PostgreSQL repo
ansible.builtin.shell:
cmd: "dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm"
executable: /bin/bash
- name: Enable pgdg14
ansible.builtin.command:
cmd: dnf config-manager --enable pgdg14
- name: Disable postgresql module
ansible.builtin.command:
cmd: dnf module disable -y postgresql
- name: Update cache
ansible.builtin.dnf:
update_cache: yes
- name: Install PostgreSQL 14
ansible.builtin.dnf:
name:
- postgresql14-server
- postgresql14
- postgresql14-devel
- jq
state: present
- name: Check if source directory exists
ansible.builtin.stat:
path: "/usr/pgsql-14/bin/"
register: src_directory
- name: Create symlinks to PostgreSQL binaries
ansible.builtin.shell:
cmd: "ln -s /usr/pgsql-14/bin/* /usr/sbin/"
executable: /bin/bash
when: src_directory.stat.exists
- name: Configure watchdog
copy:
dest: /etc/watchdog.conf
content: |
watchdog-device = /dev/watchdog
- name: Create /dev/watchdog
command: mknod /dev/watchdog c 10 130
- name: Load softdog module
command: modprobe softdog
- name: Change owner of /dev/watchdog
file:
path: /dev/watchdog
owner: postgres
group: postgres
mode: '0644'
Create Ansible etcd task
nano roles/etcd/tasks/main.ymlAdd following set of instruction:
- name: Create etcd repo
ansible.builtin.copy:
dest: /etc/yum.repos.d/etcd.repo
content: |
[etcd]
name=PostgreSQL common RPMs for RHEL / Rocky $releasever - $basearch
baseurl=http://ftp.postgresql.org/pub/repos/yum/common/pgdg-rhel9-extras/redhat/rhel-$releasever-$basearch
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/PGDG-RPM-GPG-KEY-RHEL
repo_gpgcheck = 1
owner: root
group: root
mode: '0644'
- name: Update dnf cache
ansible.builtin.dnf:
update_cache: yes
- name: Install etcd
ansible.builtin.dnf:
name: etcd
state: present
- name: Get enp0s3 IPv4 address
set_fact:
enp0s3_ipv4_address: "{{ ansible_facts['enp0s3']['ipv4']['address'] }}"
- name: Create etcd configuration file
ansible.builtin.blockinfile:
path: /etc/default/etcd
block: |
ETCD_NAME="{{ inventory_hostname }}"
ETCD_DATA_DIR="/var/lib/etcd/{{ inventory_hostname }}"
ETCD_LISTEN_PEER_URLS="http://{{ enp0s3_ipv4_address }}:2380"
ETCD_LISTEN_CLIENT_URLS="http://{{ enp0s3_ipv4_address }}:2379,http://127.0.0.1:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://{{ enp0s3_ipv4_address }}:2380"
ETCD_INITIAL_CLUSTER="{% for host in groups['dbservers'] %}{{ hostvars[host]['inventory_hostname'] }}=http://{{ hostvars[host]['enp0s3_ipv4_address'] }}:2380{% if not loop.last %},{% endif %}{% endfor %}"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://{{ enp0s3_ipv4_address }}:2379,http://127.0.0.1:2379"
ETCD_ENABLE_V2="true"
- name: Add etcd environment variables
ansible.builtin.lineinfile:
path: .bash_profile
line: "{{ item }}"
insertafter: EOF
loop:
- 'export PGDATA="/var/lib/pgsql/14/main"'
- 'export ETCDCTL_API="3"'
- 'export PATRONI_ETCD_URL="http://127.0.0.1:2379"'
- 'export PATRONI_SCOPE="pg_cluster"'
- "ENDPOINTS={% for host in groups['dbservers'] %}{{ hostvars[host]['inventory_hostname'] }}:2379{% if not loop.last %},{% endif %}{% endfor %}"
- name: Start etcd
ansible.builtin.systemd:
name: etcd
state: started
- enp0s3 for intranet with a static IP address
- enp0s8 for internet with a dynamic default IP address
Create Ansible Patroni task
nano roles/patroni/tasks/main.ymlAdd following set of instruction:
- name: Install patroni prerequisitesMake sure you replace highlighted text with yours. Save and close the editor when you are finished.
ansible.builtin.dnf:
name:
- python3
- python3-pip
- python3-devel
- gcc
- libpq-devel
state: present
- name: Install python modules
ansible.builtin.pip:
name:
- launchpadlib
- --upgrade
- testresources
- setuptools
- python-etcd
- psycopg2
- name: Install patroni
ansible.builtin.dnf:
name:
- patroni
- patroni-etcd
- watchdog
state: present
- name: Create /etc/patroni directory
ansible.builtin.file:
path: /etc/patroni
state: directory
- name: Check if /etc/patroni/patroni.yml exists
ansible.builtin.stat:
path: /etc/patroni/patroni.yml
register: config_file
- name: Configure patroni
ansible.builtin.copy:
content: |
scope: pg_cluster
namespace: /service/
name: "{{ inventory_hostname }}"
restapi:
listen: "{{ inventory_hostname }}:8008"
connect_address: "{{ inventory_hostname }}:8008"
etcd:
hosts: "{% for host in groups['dbservers'] %}{{ hostvars[host]['inventory_hostname'] }}:2379{% if not loop.last %},{% endif %}{% endfor %}"
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host replication replicator 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: "{{ inventory_hostname }}:5432"
connect_address: "{{ inventory_hostname }}:5432"
data_dir: /var/lib/pgsql/14/data
bin_dir: /usr/pgsql-14/bin
pgpass: /tmp/pgpass
authentication:
replication:
username: replicator
password: replicator
superuser:
username: postgres
password: postgres
watchdog:
mode: required
device: /dev/watchdog
safety_margin: 5
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
dest: /etc/patroni/patroni.yml
when: config_file.stat.exists == false
- name: Start Patroni
systemd:
name: patroni
state: started
- name: Waiting for patroni leader node to take charge
ansible.builtin.pause:
seconds: 30
Create Ansible keepalived task
nano roles/keepalived/tasks/main.ymlAdd following set of instruction:
- name: Install keepalivedMake sure you replace highlighted text with yours. Save and close the editor when you are finished.
ansible.builtin.dnf:
name: keepalived
state: present
- name: Add lines to sysctl.conf
ansible.builtin.lineinfile:
path: /etc/sysctl.conf
line: "{{ item }}"
insertafter: EOF
loop:
- 'net.ipv4.ip_nonlocal_bind = 1'
- 'net.ipv4.ip_forward = 1'
- name: Apply sysctl changes
ansible.builtin.command:
cmd: 'sysctl --system'
- name: Reload sysctl configuration
ansible.builtin.command:
cmd: 'sysctl -p'
- name: Backup keepalived.conf
ansible.builtin.command:
cmd: "mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.orig"
register: backup_result
ignore_errors: true
- name: Create keepalived.conf file if it doesn't exist
ansible.builtin.file:
path: /etc/keepalived/keepalived.conf
state: touch
- name: Configure keepalived
ansible.builtin.blockinfile:
path: /etc/keepalived/keepalived.conf
block: |
global_defs {
router_id LVS_1
script_user root
enable_script_security
}
vrrp_script chk_haproxy {
script "/usr/bin/killall -0 haproxy"
interval 2
weight 2
fall 2
rise 1
}
vrrp_script chk_lb {
script "/usr/bin/killall -0 keepalived"
interval 1
weight 6
fall 2
rise 1
}
vrrp_instance vrrp_1 {
interface enp0s3
{% if inventory_hostname == 'pg_node3' %}
state BACKUP
priority 99
{% elif inventory_hostname == 'pg_node2' %}
state BACKUP
priority 100
{% else %}
state MASTER
priority 101
{% endif %}
virtual_router_id 51
virtual_ipaddress {
{{ shared_ip }}
}
track_script {
chk_haproxy
chk_lb
}
}
- name: Start keepalived
ansible.builtin.systemd:
name: keepalived
state: started
Create Ansible HAProxy task
nano roles/haproxy/tasks/main.ymlAdd following set of instruction:
- name: Install HAProxyMake sure you replace the highlighted text with yours. Save and close the editor when you are finished.
ansible.builtin.dnf:
name: haproxy
state: present
- name: Backup haproxy.cfg
ansible.builtin.command:
cmd: "mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.orig"
register: backup_result
ignore_errors: true
- name: Add configuration in haproxy.cfg file
ansible.builtin.copy:
content: |
global
log 127.0.0.1 local2
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
maxconn 4000
daemon
defaults
mode tcp
log global
option tcplog
retries 3
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 3000
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen primary
bind {{ shared_ip }}:5000
option httpchk OPTIONS /master
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
{% for host in groups['dbservers'] %}
server {{ host }} {{ hostvars[host]['inventory_hostname'] }}:6432 maxconn 100 check port 8008
{% endfor %}
listen standby
bind {{ shared_ip }}:5001
balance roundrobin
option httpchk OPTIONS /replica
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
{% for host in groups['dbservers'] %}
server {{ host }} {{ hostvars[host]['inventory_hostname'] }}:6432 maxconn 100 check port 8008
{% endfor %}
dest: /etc/haproxy/haproxy.cfg
- name: Ensure /run/haproxy directory exists
file:
path: /run/haproxy
state: directory
mode: 0755
- name: Start haproxy
ansible.builtin.systemd:
name: haproxy
state: started
Create Ansible PgBouncer task
nano roles/pgbouncer/tasks/main.ymlAdd following set of instruction:
- name: Install pgbouncer
ansible.builtin.dnf:
name: pgbouncer
state: present
- name: Change permissions
ansible.builtin.file:
path: /etc/pgbouncer/
mode: '0777'
recurse: yes
- name: Check patroni master node
ansible.builtin.shell: patronictl -d etcd://{{ inventory_hostname }}:2379 list pg_cluster --format json | jq -r '.[] | select(.State == "running") | select(.Role == "Leader") | .Host'
register: master_node
changed_when: false
- name: Execute SQL command
ansible.builtin.shell: |
echo "ALTER SYSTEM SET password_encryption = 'md5'; SELECT pg_reload_conf();" | psql -U postgres
environment:
PGPASSWORD: "{{ postgres_pass }}"
when: inventory_hostname in master_node.stdout
- name: Copy pgbouncer.sql to master node
ansible.builtin.copy:
src: files/pgbouncer.sql
dest: /tmp/pgbouncer.sql
when: inventory_hostname in master_node.stdout
- name: Execute pgbouncer.sql on master node
ansible.builtin.shell: psql -Atq -U postgres -f /tmp/pgbouncer.sql
environment:
PGPASSWORD: "{{ postgres_pass }}"
when: inventory_hostname in master_node.stdout
- name: Copy userlist.sql to each node
ansible.builtin.copy:
src: files/userlist.sql
dest: /tmp/userlist.sql
- name: Execute userlist.sql
ansible.builtin.shell: psql -Atq -U postgres -f /tmp/userlist.sql
environment:
PGPASSWORD: "{{ postgres_pass }}"
- name: Add connection settings in pgbouncer.ini
ansible.builtin.replace:
path: /etc/pgbouncer/pgbouncer.ini
regexp: '^;foodb =.*$'
replace: '* = host={{ inventory_hostname }} port=5432 dbname=postgres'
- name: Update pgbouncer.ini
ansible.builtin.replace:
path: /etc/pgbouncer/pgbouncer.ini
regexp: 'listen_addr = localhost'
replace: 'listen_addr = *'
- name: Add auth_user and auth_query to pgbouncer.ini
ansible.builtin.blockinfile:
path: /etc/pgbouncer/pgbouncer.ini
block: |
auth_user = pgbouncer
auth_query = SELECT p_user, p_password FROM public.lookup($1)
insertafter: "auth_file = /etc/pgbouncer/userlist.txt"
- name: Change owner and group to postgres
ansible.builtin.file:
path: /etc/pgbouncer/
owner: postgres
group: postgres
recurse: yes
- name: Change permissions to 0644
ansible.builtin.file:
path: /etc/pgbouncer/
mode: '0644'
recurse: yes
- name: Change owner of /var/log/pgbouncer/
ansible.builtin.file:
path: /var/log/pgbouncer/
state: directory
owner: postgres
group: postgres
recurse: yes
- name: Change owner of /var/run/pgbouncer/
ansible.builtin.file:
path: /var/run/pgbouncer/
state: directory
owner: postgres
group: postgres
recurse: yes
- name: Start pgbouncer
ansible.builtin.shell: pgbouncer -d -u postgres /etc/pgbouncer/pgbouncer.ini
This process requires us to configure PgBouncer with a list of valid credentials. This can be done in a number of ways, such as providing a static list of usernames and passwords, or configuring PgBouncer to query a database for the current valid credentials.
If user credentials change frequently, constantly updating the user list can become tedious. In such cases, it’s more efficient to use an “authentication user” who can connect to the database and retrieve the password.
To ensure the database password isn’t visible to everyone, we restrict password access to this authentication user only.
The pg_shadow is accessible solely to superusers. Therefore, we create a SECURITY DEFINER function to grant pgbouncer access to the passwords.
Create PgBouncer SECURITY DEFINER Function
nano roles/pgbouncer/files/pgbouncer.sqlAdd following content:
CREATE ROLE pgbouncer LOGIN ENCRYPTED PASSWORD 'pgbouncer' VALID UNTIL 'infinity';Save and close the editor when you are finished.
CREATE FUNCTION public.lookup (
INOUT p_user name,
OUT p_password text
) RETURNS record
LANGUAGE sql SECURITY DEFINER SET search_path = pg_catalog AS
$$SELECT usename, passwd FROM pg_shadow WHERE usename = p_user$$;
Since the auth_query connection will be established with the target database, you need to add the function to each database you wish to access through pgbouncer.
nano roles/pgbouncer/files/userlist.sqlAdd following content:
\o /etc/pgbouncer/userlist.txt
SELECT concat('"', usename, '" "', passwd, '"') FROM pg_shadow WHERE usename = 'pgbouncer';
Encrypt Ansible Vault
To encrypt a variable with Ansible Vault, use the following command:
ansible-vault encrypt_string 'your_postgress_password' --name 'postgres_pass'

Create an Ansible Playbook
nano setup.yml
---
- hosts: dbservers
become: true
vars:
shared_ip:192.168.0.200
postgres_pass: !vault |
$ANSIBLE_VAULT;1.1;AES256
363837386436306430393639656130616635313765393265643665346139326234323763396132363933353938626663326137663430626566333964633331360a336338623538613133343836323636356238643961656363646266313234373239316363333332643165633137663135383161323363333266623962316634370a3838636536383230633332323866643765343738666362623130343962306136
roles:
- common
- postgres
- etcd
- patroni
- keepalived
- haproxy
- pgbouncer
Check Ansible Playbooks Syntax
It is a recommended to check syntax errors in ansible playbooks so that you can fix the issue beforehand.ansible-playbook --syntax setup.yml


Run Ansible Playbook
ansible-playbook -K setup.yml--ask-vault-pass-v

Explanation:
- Become password is your ssh user password of your dbservers needed to execute tasks with sudo privileges.
The next prompt will ask you to enter ansible Vault password so that setup.yml can use postgres_pass variable.

Rerun Ansible Playbook
If Ansible playbook failed at any task for any reason, stop there, fix the issue, and rerun the playbook starting from the failed task.ansible-playbook --start-at-task "Your failed task name" setup.yml--ask-vault-pass-v

Test PostgreSQL HA Cluster
nano ~/.pgpass
shared_ip:5001:postgres:TypePostgresPassHere:postgres
shared_ip:5000:postgres:TypePostgresPassHere:postgres
psql -h shared_ip -p 5000 -U postgres -t
Verify PostgreSQL HA Cluster Load Balancing
psql -h shared_ip -p 5001 -U postgres -t -c "select inet_server_addr()"
psql -h shared_ip -p 5001 -U postgres -t -c "select inet_server_addr()"
psql -h shared_ip -p 5000 -U postgres -t -c "select inet_server_addr()"
HAProxy Stats Dashboard
You can access HAProxy stats dashboard by typing http://shared_ip:7000/ in your browser address bar.

Please note that, in this particular scenario, it just so happens that the second node in the cluster is promoted to leader. This might not always be the case and it is equally likely that the 3rd node may be promoted to leader.
Verify PostgreSQL Database Replication
Create a test database to see if it is replicated to other nodes in the cluster. For this guide, we will use (psql) to connect to database via haproxy like below:
psql -hshared_ip-p 5000 -U postgres -t
Create a test database like below:
create database testDB;
create user testuser with encrypted password 'mystrongpass';
grant all privileges on database testDB to testuser;
\qConnect to testDB via shared_ip:5001 to see if it is replicated to your replica nodes:
psql -h shared_ip -p 5001 testuser -d testDBThis will connect you to your testDB on a replica node which means database replication is working as expected.
Verify Patroni Failover
patronictl -d etcd://127.0.0.1:2379 listpg_cluster

patronictl -d etcd://127.0.0.1:2379 historypg_cluster
patronictl -d etcd://127.0.0.1:2379failoverpg_cluster
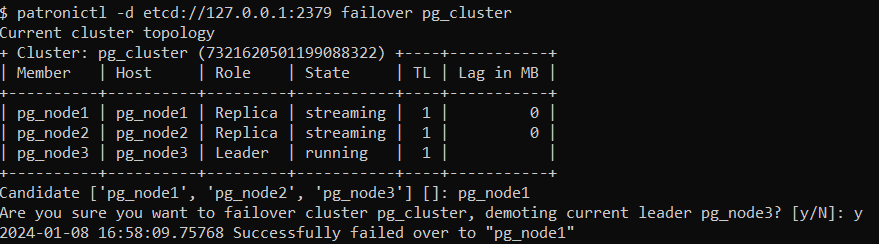
I have promoted pg_node1 as the leader node in the cluster.
Disable Patroni Auto Failover
In some cases it is necessary to perform maintenance task on a single node such as applying patches or release updates. When you manually disable auto failover, patroni won’t change the state of the PostgreSQL HA cluster.
You can disable auto failover with below command:
patronictl -d etcd://127.0.0.1:2379 pause pg_cluster
Patroni Switchover
There
are two possibilities to run a switchover, either in scheduled mode or
immediately. At the given time, the switchover will take place, and you
will see an entry of switchover activity in the log file.
patronictl -d etcd://127.0.0.1:2379 switchover pg_cluster --master your_leader_node --candidate your_replica_nodeSimulate Patroni Cluster Failure Scenario
To simulate failure scenarios in production environment, we will execute continuous reads and writes to the database using a simple Python script as we are interested in observing the state of the cluster upon a server failure.
You should have a workstation (physical or virtual) with any of your favorite Linux distribution (Ubuntu or Debian) installed.
Type following command to install PostgreSQL client, and driver for python on your Linux workstation:
sudo apt -y install postgresql-client python3-psycopg2
cd ~
git clone https://github.com/manwerjalil/pgscripts.git
chmod +x ~/pgscripts/pgsqlhatest.py
nano~/pgscripts/pgsqlhatest.py
# CONNECTION DETAILS
host = "shared_ip"
dbname = "postgres"
user = "postgres"
password = "Type_postgres_password_Here"
We will use tmux terminal for multiple tabs on a single screen to monitor state of the patroni cluster in real time:psql -h shared_ip -p 5000 -U postgres -t -c "CREATE TABLE PGSQLHATEST (TM TIMESTAMP);"psql -h shared_ip -p 5000 -U postgres -t -c "CREATE UNIQUE INDEX idx_pgsqlhatext ON pgsqlhatest (tm desc);"
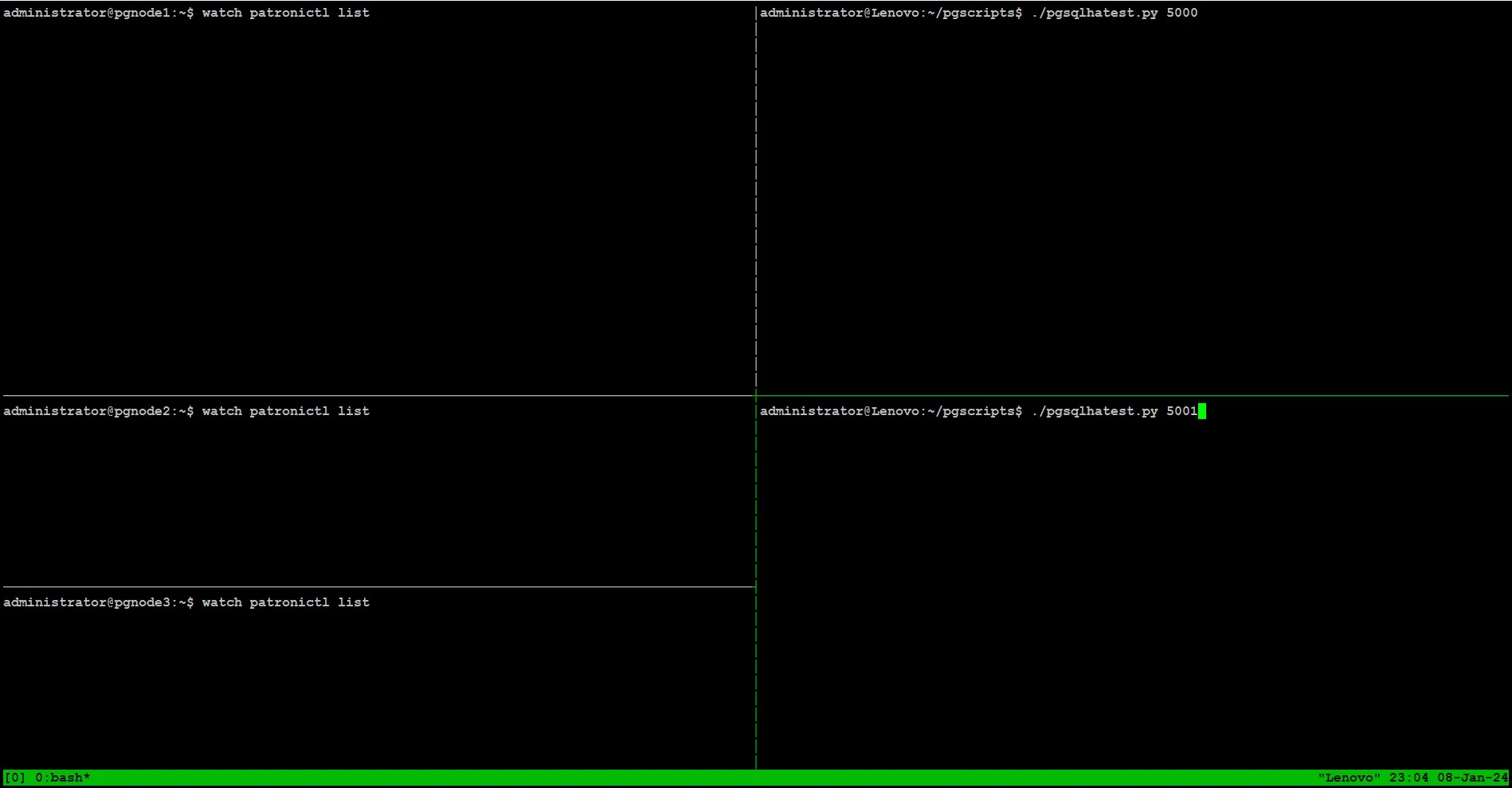
On the right side of the screen, we are running python script sending writes through port 5000, and reads through port 5001 from our workstation:
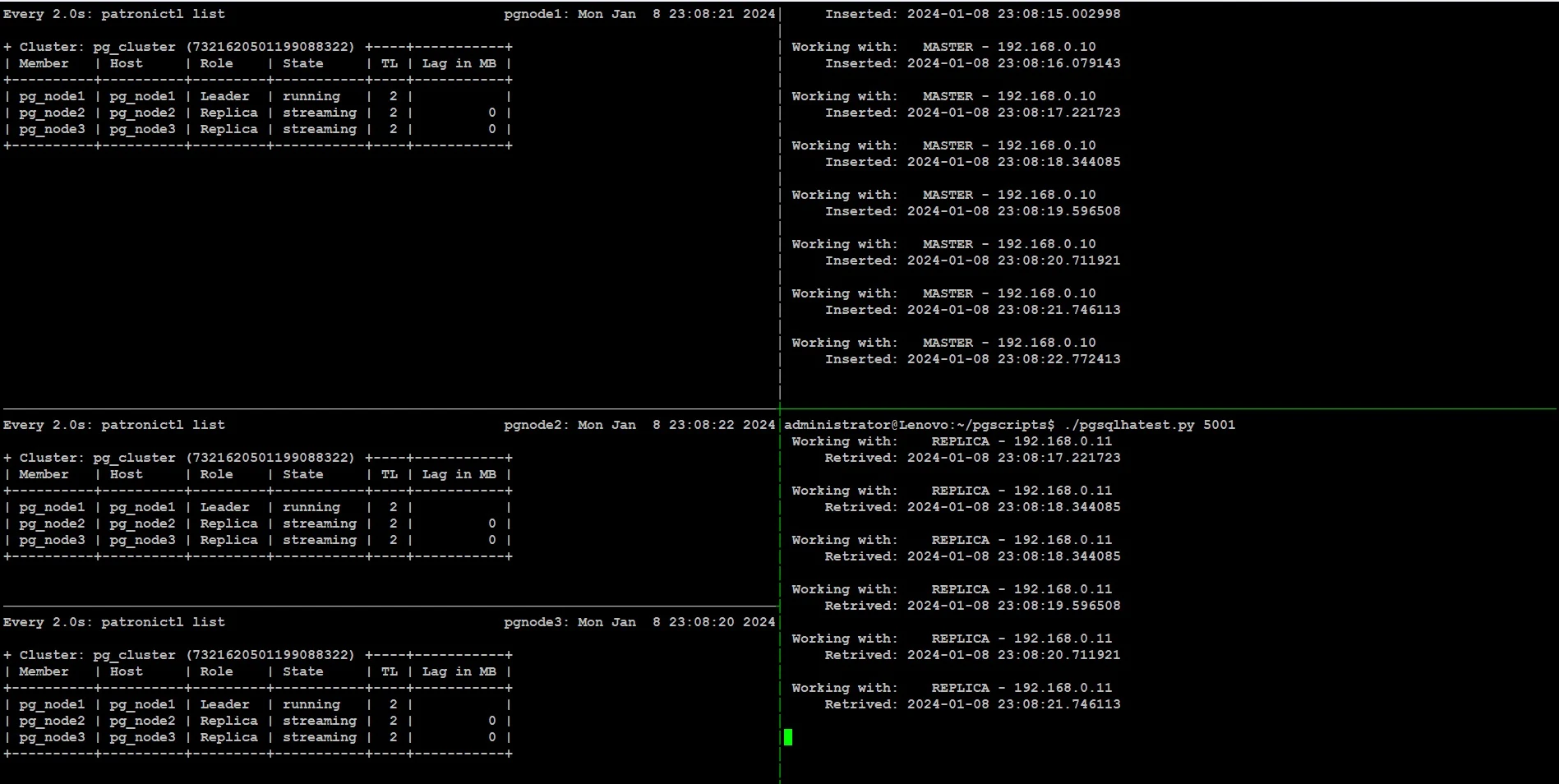
sudo systemctl stop pg_node1sudo systemctl start pg_node1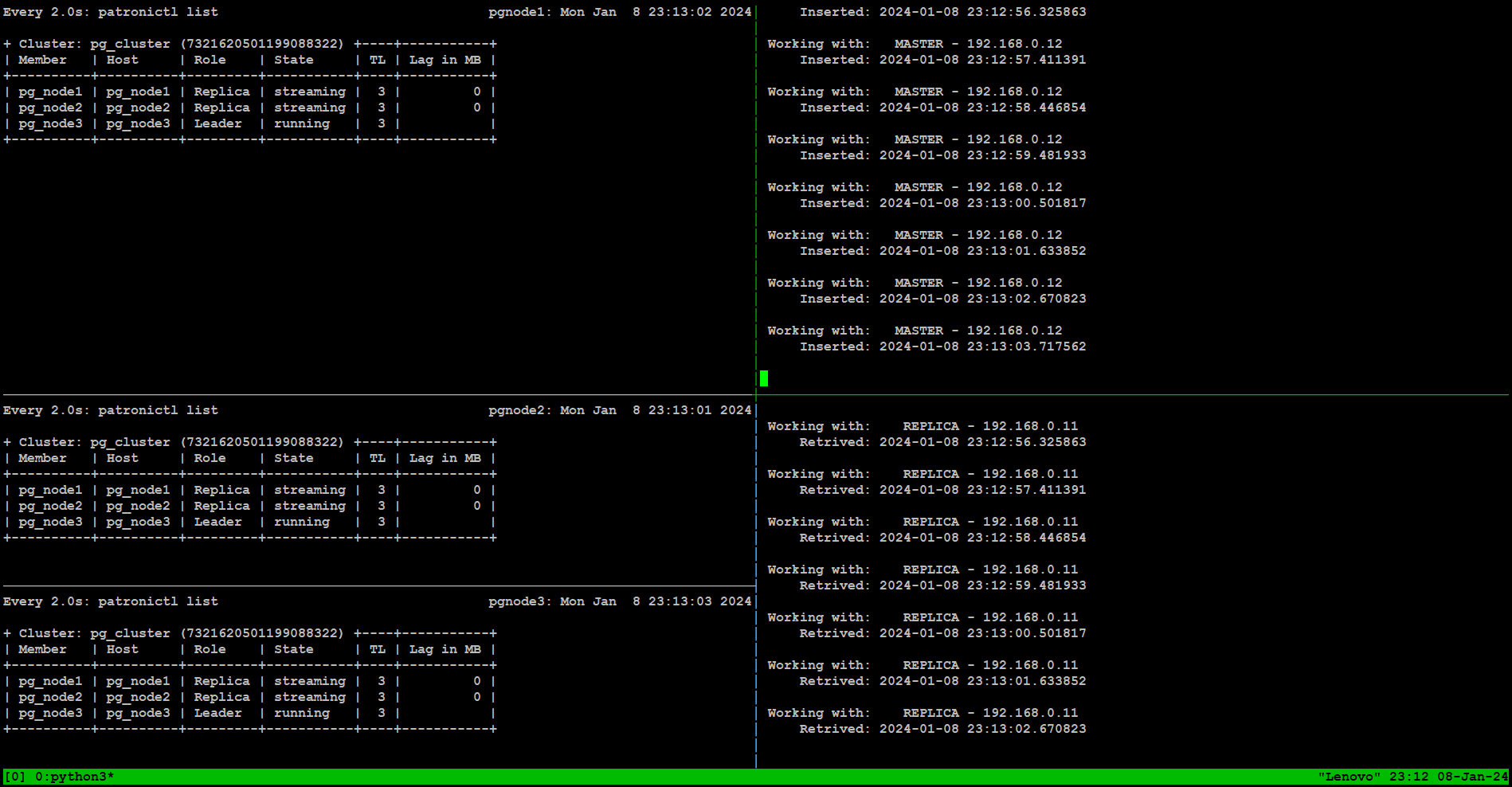
PostgreSQL HA Cluster Environment Failure Scenarios
- Loss of network connectivity
- Power breakdown
When simulating these tests, you should continuously monitor how the patroni cluster re-adjusts itself and how it affects read and write traffic for each failure scenario.


No comments: